Why is it so hard to have data that actually works?
It should be easy. But few companies actually manage to have data that helps their teams make better decisions to build better products and user experiences.
What each team needs to do with data
Think about the different teams in a B2B company with a digital product. All of them use behavioral data from users. Essentially the same data. But each team needs it for completely different things.
I'll start at the end. With the happy story. With what should happen when data actually works.
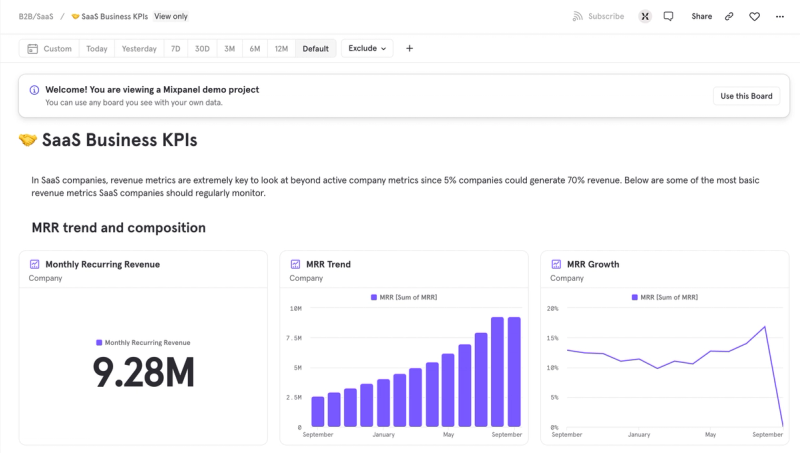
The Growth team needs to understand how their initiatives are impacting product adoption. Are the people who signed up actually using the product? Did they reach that first moment of value? Are they converting to a paid subscription? Every campaign, every experiment, every onboarding change needs immediate feedback on whether it moved any of those metrics.
The CRM team needs to segment, personalize, and test channels, messages, and timings at scale. If a user signed up but never reached the first moment of value, what message do I send? Through which channel? At what time? To do that well, they need the product's core events in their tools. Not in a Google Sheet, not in a weekly report. In real time, so they can act.
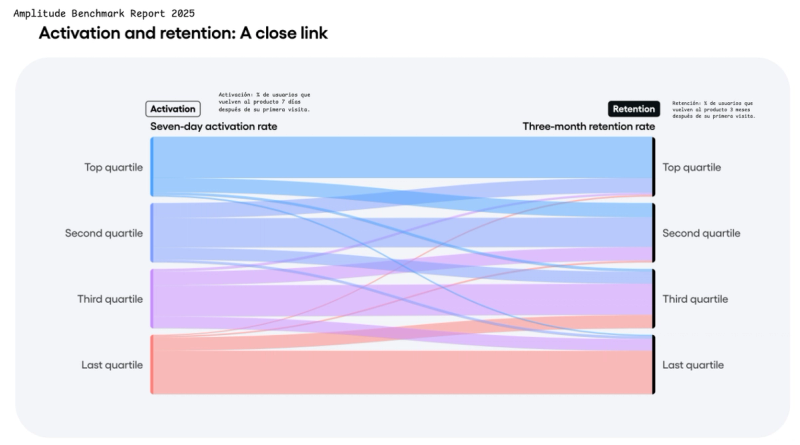
The Product team needs to understand whether the features they ship drive real adoption. How many users reached the moment of value? How many repeated it? Where is the drop-off? Which user cohorts have the highest retention?
The Sales team needs to understand what is happening inside accounts that are in trial or up for renewal. An account that invited 10 users but only one accepted is a very different signal from one with 10 active users. That difference, visible in product data, can be the difference between a renewal and a churn.
The Revenue / RevOps team needs context to build churn prediction models, cohort models, and expansion signals. Which accounts are at risk? Which ones are ready for an upgrade? That information does not live only in the CRM. It lives in product behavioral data and in the predictive models built by the Data Science team.
All those teams have different objectives, but the data should be the same.
When that works, each team can move fast and make better decisions. When it does not, teams are misaligned and heading in different directions.
Why this seems easy but isn't
The problem is not the amount of data. I keep seeing companies with 1,000+ events that are useless. Most already have data, tools, dashboards.
The problem is that everything is out of sync.
The Product team is tracking in their analytics platform. The CRM team has their lifecycle tool with data coming from some integration. The Sales team lives in HubSpot or Salesforce. The Data team has the warehouse with backend transactional data. And if there is a Data Science team, it has its own pipelines and its own models.
And then these things happen:
- The same user has different IDs in every system. Nobody knows it's the same person.
- The event that Product calls feature_x_used never reaches the CRM, so the CRM team cannot use it to trigger a message.
- Sales sees an account marked as "active" in the CRM, but they haven't logged into the product in three weeks.
- The Data Science team built an excellent churn prediction model, but the scores don't reach Sales in time to act.
- Android and iOS events have different names and different properties. Comparing platforms is a manual job every time.
This is not a tooling problem. It is a data architecture problem.
And when that architecture is missing or broken, the cost is real: teams depend on engineering for every segment, campaigns go out on stale or incomplete data, and decisions that look data-driven actually are not.
The framework: The Modern Growth Stack
At Bildung we have been working for years with data, product, and growth teams. Some very mature, others just starting out. Some with a consolidated warehouse, others with one SDK connected to one tool and nothing else.
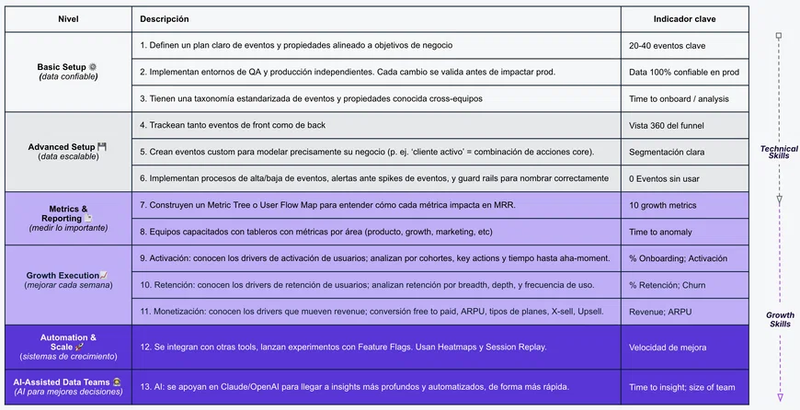
What we consistently see is that, regardless of where each team is today, the path always has the same phases. You may be more or less advanced in each one, but all of them matter.
Phase 1: Business Context
The starting point is not what we track. It is what decisions each team needs to make. From there you derive the metrics that matter, and from there the events and properties that answer them. The tracking plan is the output of this process, not the starting point. Without this phase, everything that follows is noise.
Phase 2: Data Architecture Design
Given what you need to activate, what is the architecture that enables it? It is not the same answer for everyone. When does a CDP like Segment or RudderStack make sense? When are native SDKs enough? When is the warehouse the center? There are different possible architectures and the right one depends on your team, your sources, and what you want to do.
Phase 3: Getting data where it needs to be
The goal of this phase is to have the right data, in real time, in every tool that needs it. With properties correctly mapped and consistent across sources. A backend event should always be the most reliable source. An iOS event and an Android event should have the same name and the same properties. Data Science models should reach the CRM in time to act. This is not just a technical pipeline problem. It is a consistency and reliability problem.
Phase 4: Data Activation
With clean data flowing, each team operates in their tool. The CRM team segments, personalizes, and tests channels, messages, and timings at scale using OneSignal, Braze, CleverTap, or whatever they use. The Product team measures funnels and adoption in Mixpanel, Amplitude, Pendo. The Revenue team has their cohort and churn models in BI. And increasingly, experimentation and feature flags live here too: deciding which feature to roll out to which segment, measuring impact before a full release.
The goal is not to have data build the segment for you. It is to never have to ask for it again.
The AI layer: what is already changing and what is not yet
Honestly, this is something I think about differently every week.
Everything moves so fast that some things that were done one way six months ago are done completely differently today. And some things that will change radically in the near future are still the same today.
In Business Context, not much changes for now. Business questions are still human. What is changing is that more and more you will have agents consuming that data, not just dashboards. That starts to shift how you need to think about event design.
In implementation, what is already clearly felt is speed. Before, instrumenting 30 key events was a full sprint. Today it should take less than an hour. The product-data cycle has shortened in a way that was not possible a year ago.
In activation is where the most change is coming. The agent that decides on centralized, clean data replaces manual A/B testing, personalizes in real time, acts on signals no human could process at that scale. But for that to work, the foundation has to be in place.
AI can help you decide faster, but if you are deciding on inconsistent data, you will basically drive your product in the wrong direction faster. Speed does not help if the direction is wrong.
I do not have a 100% definitive answer on all of this. Nobody does. What is clear: data architecture does not become less important with AI. It becomes more important.
This is the foundation of what we think about The Modern Growth Stack.
In the coming weeks I will go phase by phase: how to define what data you need, how to design the architecture, how to implement it well, and how to activate.
Which phase is your team in today?