¿Por qué es tan difícil tener datos que realmente sirvan?
Debería ser fácil. Pero pocas empresas realmente logran tener datos que ayuden a sus equipos a tomar mejores decisiones para crear mejores productos y experiencias de usuario.
Lo que cada equipo necesita hacer con los datos
Pensemos en los distintos equipos de una empresa B2B con un producto digital. Todos usan datos de comportamiento de usuarios. Los mismos datos, básicamente. Pero cada uno los necesita para cosas distintas.
Arranco por el final. Por la historia feliz. Por lo que debería pasar cuando los datos funcionan de verdad.
El equipo de Growth necesita entender cómo sus iniciativas están impactando la adopción y retención del producto. ¿Las personas que se registraron empezaron a usar el producto? ¿Llegaron a ese primer momento de valor? ¿Están convirtiendo a una suscripción paga? ¿cómo impacta a la retención largo plazo?
Cada campaña, cada experimento, cada cambio de onboarding necesita feedback inmediato sobre si movió alguna de esas métricas.
El equipo de CRM necesita poder segmentar, personalizar y testear canales, mensajes y timings a escala. Si el usuario se registró pero no llegó al primer momento de valor, ¿qué mensaje le mando? ¿Por qué canal? ¿En qué momento? Para hacer eso bien, necesitan los eventos core del producto en sus herramientas. No en un Google Sheet, no en un reporte semanal. En tiempo real, para poder actuar.
El equipo de Producto necesita entender si los features que lanza generan adopción real. ¿Cuántos usuarios llegaron al momento de valor? ¿Cuántos repitieron? ¿Dónde está el drop-off? ¿Qué cohortes de usuarios tienen mayor retención?
El equipo de Sales necesita entender qué está pasando dentro de las cuentas que están en trial o próximas a renovar. Una cuenta que invitó a 10 usuarios pero solo uno aceptó la invitación es una señal muy distinta a una que tiene 10 usuarios activos. Esa diferencia, visible en los datos del producto, puede ser la diferencia entre una renovación y un churn.
El equipo de Revenue / RevOps necesita contexto para construir modelos de predicción de churn, modelos de cohorts, señales de expansión. ¿Qué cuentas están en riesgo? ¿Cuáles están listas para un upgrade? Esa información no vive solo en el CRM. Vive en los datos de comportamiento del producto y en los modelos predictivos que construye el equipo de Data Science.
Todos esos equipos tienen distintos objetivos, pero los datos deberían ser los mismos.
Cuando eso funciona bien, cada equipo puede moverse rápido y tomar mejores decisiones. Cuando no funciona, los equipos están descoordinados y yendo en distintas direcciones.
Por qué esto parece fácil y no lo es
El problema no es la cantidad de datos. No paro de ver empresas que tienen +1000 eventos que no sirven para nada. La mayoría ya tiene datos, herramientas, dashboards.
El problema es que todo está desincronizado.
El equipo de Producto está trackeando en su plataforma de analytics. El equipo de CRM tiene su herramienta de lifecycle con los datos que llegaron de alguna integración. El equipo de Sales vive en HubSpot o Salesforce. El equipo de Data tiene el warehouse con datos transaccionales del backend. Y si hay Data Science, tiene sus propios pipelines y sus propios modelos.
Y de pronto pasan estas cosas:
- El mismo usuario tiene IDs distintos en cada sistema. Nadie sabe que es la misma persona.
- El evento que Producto llama feature_x_used no llega al CRM, entonces el equipo de CRM no puede usarlo para disparar un mensaje.
- Sales ve una cuenta "activa" en el CRM pero en el producto llevan tres semanas sin entrar.
- El equipo de Data Science armó un modelo de churn prediction excelente, pero los scores no llegan a Sales a tiempo para actuar.
- Los eventos de Android y iOS se llaman distinto, con propiedades distintas. Comparar plataformas es un trabajo manual cada vez.
Esto no es un problema de herramientas. Es un problema de arquitectura de datos.
Y cuando esa arquitectura no existe o está rota, el costo es concreto: los equipos dependen de ingeniería para cada segmento, las campañas se lanzan sobre datos viejos o incompletos, y las decisiones que parecen data-driven en realidad no lo son.
El framework: The Modern Growth Stack
En Bildung venimos trabajando hace años con equipos de data, de producto, de growth. Algunos muy maduros, otros recién arrancando.
Algunos con un warehouse consolidado, otros con un SDK conectado a una herramienta y nada más.
Lo que sí vemos consistentemente es que, independientemente de dónde esté cada equipo hoy, el camino tiene siempre las mismas fases. Podés estar más o menos avanzado en cada una, pero todas importan.
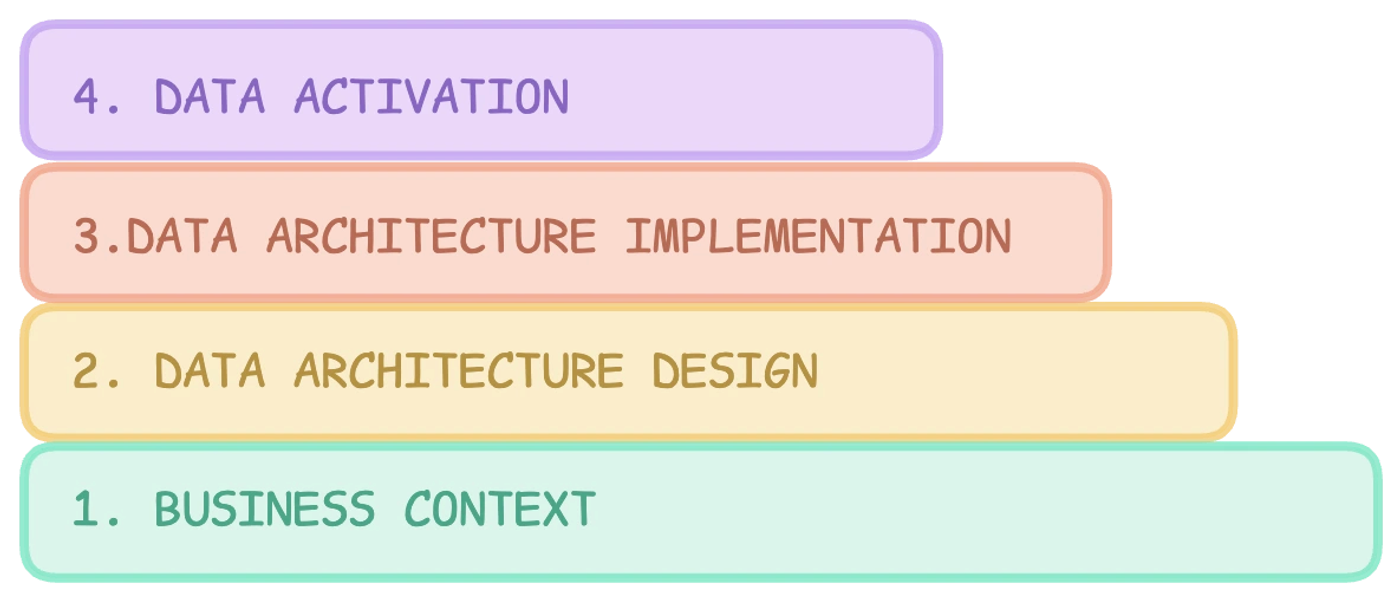
Fase 1: Business to Data Context
El punto de partida no es qué trackeamos, sino que ¿para qué precisamos datos?
- ¿Cuál es el objetivo de cada equipo, qué preguntas de negocio quieren poder responder y qué decisiones necesitan tomar con datos?
- De ahí se derivan las métricas que importan,
- y de ahí recién los eventos y propiedades que ayudan a responderlas.
No más de 30 eventos deberían ser más que suficiente. El tracking plan es el output de este proceso, no el punto de partida. Sin esta fase, todo lo que sigue es ruido.
El desafío de esta etapa es que realmente sea un ejercicio que se hace entre todos los equipos. Que realmente se entienda cuál es el objetivo de tener datos, qué tipo de decisiones queremos tomar.
No sólo a través de distintos equipos Growth / Producto / CRM / Sales… sino que dentro de producto por ejemplo, que todas los squads esten alineados.
He visto equipos de producto donde un squad tiene claro cuáles son las top 3 métricas importantes para ellos, y otros squad donde quieren trackear absolutamente todas las acciones que puede realizar un usuario - sin estrategia por detrás.
Fase 2: Data Architecture Design
Dado lo que ya definimos para qué vas a necesitar los datos, ¿cuál es la arquitectura que te lo permite?
No es la misma respuesta para todos. Distintos productos tendrán distinta madurez.
Si soy una startup dando mis primeros pasos no hace falta tener una arquitectura super compleja con CDP + Data Warehouse. Pero si ya soy suficientemente maduro y con un volumen interesante, quizás si.
¿Cuándo tiene sentido un CDP como Segment o RudderStack? ¿Cuándo alcanza con los SDKs nativos? ¿Cuándo preciso un data warehouse centralizado? Hay distintas arquitecturas posibles y la que conviene depende del equipo, las fuentes y lo que querés hacer.
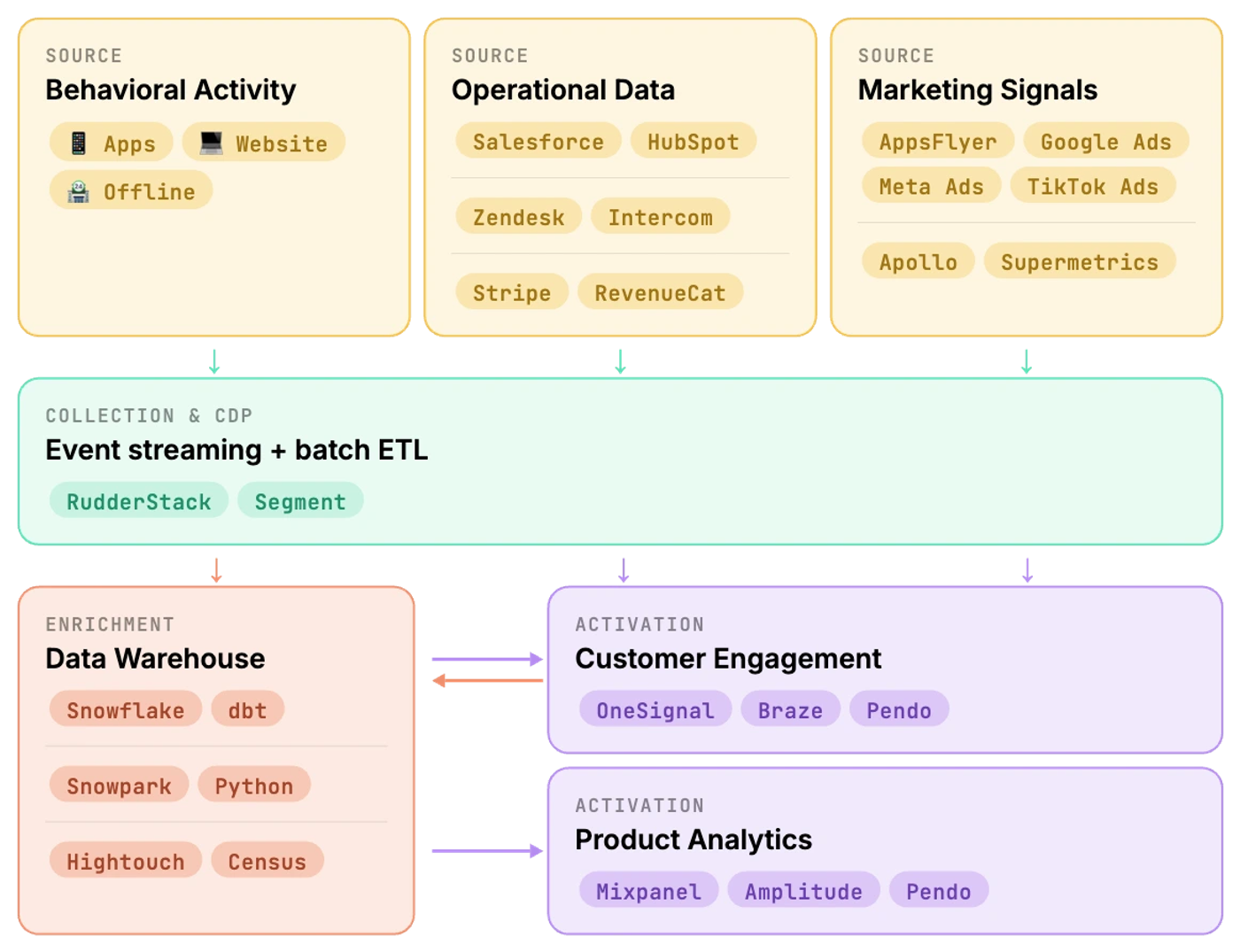
Fase 3: Llevar los datos a donde tienen que estar
El objetivo de esta fase es poder tener los datos correctos, en tiempo real, en cada herramienta que los necesita.
Con consistencia entre fuentes y destinos. De tal manera que los equipos puedan tomar decisiones con confianza en los datos. Y no que distintos equipos / herramientas cuenten historias diferentes.
Que un evento de backend sea siempre la fuente más confiable. Que un evento de iOS y uno de Android se llamen igual y tengan las mismas propiedades.
Que los modelos de Data Science puedan llegar al CRM en tiempo para actuar.
No es solo un problema técnico de pipelines. Es un problema de consistencia y confiabilidad.
Fase 4: Data Activation
Con los datos limpios y fluyendo, cada equipo opera en su herramienta.
- El equipo de CRM segmenta, personaliza y testea canales, mensajes y timings en escala usando OneSignal, Braze, CleverTap o lo que usen.
- El equipo de Producto mide activación, retención y monetización en Mixpanel, Amplitude, Pendo. O ejecutan A/B test de producto con feature flags y miden su impacto.
- El equipo de Sales tiene sus modelos de cohorts y churn idealmente en su Salesforce / Hubspot.
Cada equipo aprende a operar con datos. A entender cuándo precisa datos nuevos y cómo pedirlos.
con AI: lo que ya cambia y lo que todavía no
Honestamente, esto es algo que pienso distinto cada semana.
Todo se mueve tan rápido que hay cosas que hace seis meses se hacían de una manera y hoy ya no. Y hay cosas que en el futuro próximo van a cambiar radicalmente y hoy todavía no.
En Business Context cambia poco por ahora. Las preguntas de negocio siguen siendo humanas. Lo que sí está cambiando es que cada vez más vas a tener agentes consumiendo esos datos, no solo dashboards. Eso empieza a cambiar cómo tenés que pensar el diseño de los eventos.
En la implementación, lo que ya se siente claramente es velocidad. Antes instrumentar 30 eventos clave era una tarea de un sprint entero. Hoy debería tomar menos de una hora. El ciclo producto-data se acortó de una forma que hace un año no era posible.
En activación es donde más va a cambiar. El agente que decide sobre datos centralizados y limpios reemplaza el A/B manual, personaliza en tiempo real, actúa sobre señales que ningún humano podría procesar a esa escala. Pero para que eso funcione, la base tiene que estar.
AI te puede ayudar a decidir más rápido, pero si estás decidiendo sobre datos inconsistentes, básicamente vas a llevar tu producto en una dirección equivocada más rápido. La velocidad no ayuda si la dirección está mal.
No tengo una respuesta 100% cerrada sobre todo esto. Nadie la tiene. Lo que sí es claro: la arquitectura de datos no se vuelve menos importante con AI. Se vuelve más importante.
Esto es la base de lo que pensamos sobre The Modern Growth Stack.
En las próximas semanas bajo fase por fase: cómo definir qué datos necesitás, cómo diseñar la arquitectura, cómo implementarla bien, y cómo activar.
¿Estos son problemas que estás teniendo hoy? Hablemos.