Por que é tão difícil ter dados que realmente funcionam?
Deveria ser fácil. Mas poucas empresas realmente conseguem ter dados que ajudem suas equipes a tomar melhores decisões para criar melhores produtos e experiências de usuário.
O que cada equipe precisa fazer com os dados
Pense nas diferentes equipes de uma empresa B2B com um produto digital. Todas usam dados comportamentais de usuários. Essencialmente os mesmos dados. Mas cada equipe precisa deles para coisas completamente diferentes.
Vou começar pelo final. Pela história feliz. Pelo que deveria acontecer quando os dados realmente funcionam.
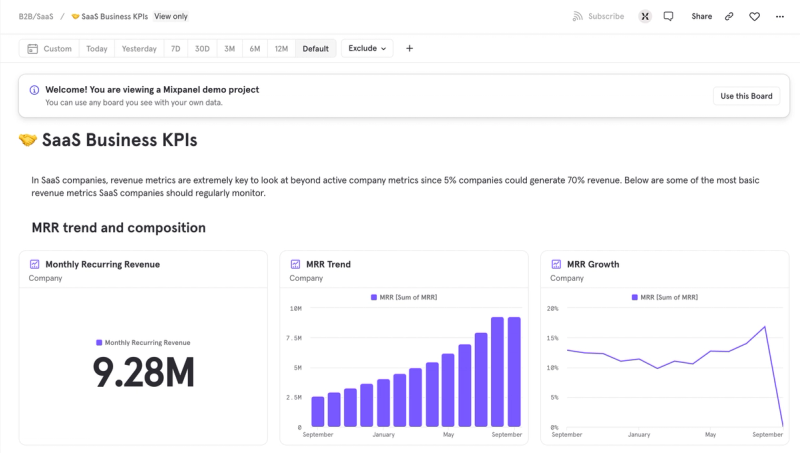
A equipe de Growth precisa entender como suas iniciativas estão impactando a adoção do produto. As pessoas que se cadastraram começaram a usar o produto? Chegaram ao primeiro momento de valor? Estão convertendo para uma assinatura paga? Cada campanha, cada experimento, cada mudança no onboarding precisa de feedback imediato sobre se moveu alguma dessas métricas.
A equipe de CRM precisa segmentar, personalizar e testar canais, mensagens e timings em escala. Se o usuário se cadastrou mas não chegou ao primeiro momento de valor, qual mensagem envio? Por qual canal? Em qual momento? Para fazer isso bem, precisam dos eventos core do produto em suas ferramentas. Não em uma planilha, não em um relatório semanal. Em tempo real, para poder agir.
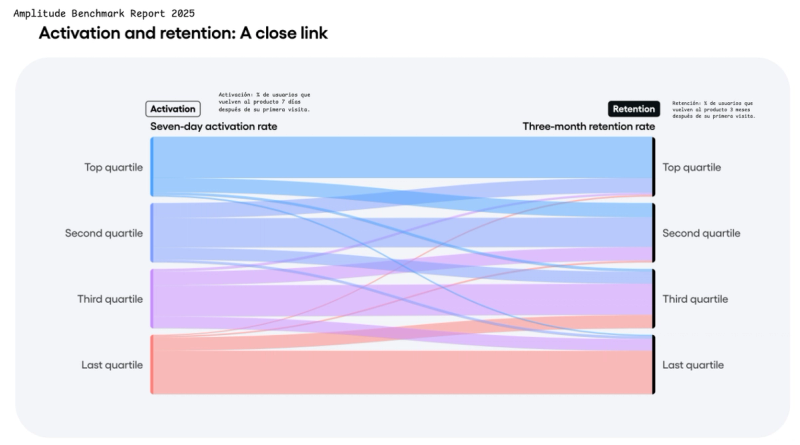
A equipe de Produto precisa entender se os features que lança geram adoção real. Quantos usuários chegaram ao momento de valor? Quantos repetiram? Onde está o drop-off? Quais coortes de usuários têm maior retenção?
A equipe de Sales precisa entender o que está acontecendo dentro das contas que estão em trial ou próximas de renovar. Uma conta que convidou 10 usuários mas apenas um aceitou é um sinal muito diferente de uma que tem 10 usuários ativos. Essa diferença, visível nos dados do produto, pode ser a diferença entre uma renovação e um churn.
A equipe de Revenue / RevOps precisa de contexto para construir modelos de predição de churn, modelos de coortes e sinais de expansão. Quais contas estão em risco? Quais estão prontas para um upgrade? Essa informação não vive apenas no CRM. Vive nos dados comportamentais do produto e nos modelos preditivos construídos pela equipe de Data Science.
Todas essas equipes têm objetivos diferentes, mas os dados deveriam ser os mesmos.
Quando isso funciona, cada equipe consegue se mover rápido e tomar melhores decisões. Quando não funciona, as equipes estão descoordinadas e indo em direções diferentes.
Por que isso parece fácil mas não é
O problema não é a quantidade de dados. Não paro de ver empresas com mais de 1.000 eventos que não servem para nada. A maioria já tem dados, ferramentas, dashboards.
O problema é que tudo está dessincronizado.
A equipe de Produto está fazendo tracking na sua plataforma de analytics. A equipe de CRM tem sua ferramenta de lifecycle com dados que chegaram de alguma integração. A equipe de Sales vive no HubSpot ou Salesforce. A equipe de Data tem o warehouse com dados transacionais do backend. E se há Data Science, tem seus próprios pipelines e seus próprios modelos.
E de repente acontecem estas coisas:
- O mesmo usuário tem IDs diferentes em cada sistema. Ninguém sabe que é a mesma pessoa.
- O evento que Produto chama de feature_x_used nunca chega ao CRM, então a equipe de CRM não pode usá-lo para disparar uma mensagem.
- Sales vê uma conta marcada como "ativa" no CRM, mas faz três semanas que não entram no produto.
- A equipe de Data Science construiu um excelente modelo de predição de churn, mas os scores não chegam ao Sales a tempo de agir.
- Os eventos de Android e iOS têm nomes diferentes e propriedades diferentes. Comparar plataformas é um trabalho manual toda vez.
Esse não é um problema de ferramentas. É um problema de arquitetura de dados.
E quando essa arquitetura não existe ou está quebrada, o custo é real: as equipes dependem de engenharia para cada segmento, as campanhas saem com dados antigos ou incompletos, e as decisões que parecem data-driven na verdade não são.
O framework: The Modern Growth Stack
Na Bildung trabalhamos há anos com equipes de data, produto e growth. Algumas muito maduras, outras começando do zero. Algumas com um warehouse consolidado, outras com um SDK conectado a uma ferramenta e nada mais.
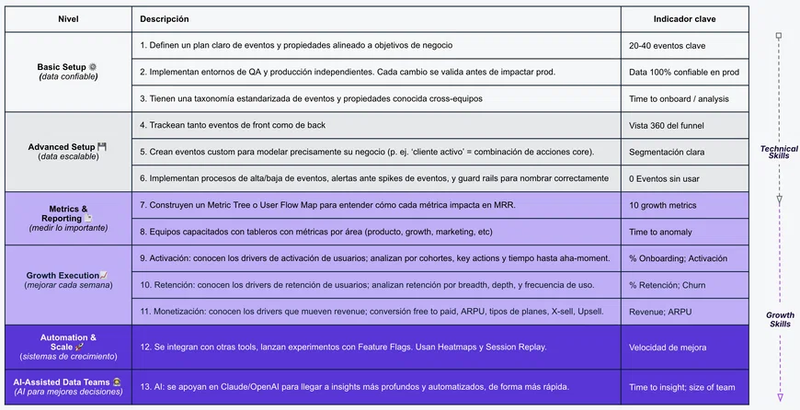
O que vemos consistentemente é que, independentemente de onde cada equipe está hoje, o caminho sempre tem as mesmas fases. Você pode estar mais ou menos avançado em cada uma, mas todas importam.
Fase 1: Business Context
O ponto de partida não é o que trackear. É quais decisões cada equipe precisa tomar. A partir daí se derivam as métricas que importam, e a partir daí os eventos e propriedades que as respondem. O tracking plan é o output desse processo, não o ponto de partida. Sem essa fase, tudo que segue é ruído.
Fase 2: Data Architecture Design
Dado o que você precisa ativar, qual é a arquitetura que permite isso? Não é a mesma resposta para todos. Quando faz sentido um CDP como Segment ou RudderStack? Quando os SDKs nativos são suficientes? Quando o warehouse é o centro? Existem diferentes arquiteturas possíveis e a que convém depende da sua equipe, das suas fontes e do que você quer fazer.
Fase 3: Levar os dados para onde precisam estar
O objetivo desta fase é ter os dados corretos, em tempo real, em cada ferramenta que os precisa. Com propriedades bem mapeadas e consistentes entre fontes. Um evento de backend deve sempre ser a fonte mais confiável. Um evento de iOS e um de Android devem ter o mesmo nome e as mesmas propriedades. Os modelos de Data Science devem chegar ao CRM em tempo para agir. Não é apenas um problema técnico de pipelines. É um problema de consistência e confiabilidade.
Fase 4: Data Activation
Com dados limpos fluindo, cada equipe opera na sua ferramenta. A equipe de CRM segmenta, personaliza e testa canais, mensagens e timings em escala usando OneSignal, Braze, CleverTap ou o que usarem. A equipe de Produto mede funnels e adoção em Mixpanel, Amplitude, Pendo. A equipe de Revenue tem seus modelos de coortes e churn em BI. E cada vez mais, experimentação e feature flags também vivem aqui: decidir qual feature lançar para qual segmento, medir o impacto antes de um lançamento completo.
O objetivo não é que data construa o segmento para você. É nunca mais precisar pedir.
A camada de AI: o que já está mudando e o que ainda não
Honestamente, isso é algo que penso de forma diferente toda semana.
Tudo se move tão rápido que algumas coisas que eram feitas de um jeito seis meses atrás são feitas de forma completamente diferente hoje. E algumas coisas que vão mudar radicalmente em breve ainda são iguais hoje.
No Business Context, pouca coisa muda por enquanto. As perguntas de negócio ainda são humanas. O que está mudando é que cada vez mais você vai ter agentes consumindo esses dados, não apenas dashboards. Isso começa a mudar como você precisa pensar no design dos eventos.
Na implementação, o que já se sente claramente é velocidade. Antes, instrumentar 30 eventos-chave era uma tarefa de um sprint inteiro. Hoje deveria levar menos de uma hora. O ciclo produto-data encurtou de uma forma que não era possível há um ano.
Na ativação é onde mais vai mudar. O agente que decide sobre dados centralizados e limpos substitui o A/B manual, personaliza em tempo real, age sobre sinais que nenhum humano poderia processar nessa escala. Mas para isso funcionar, a base precisa estar no lugar.
A AI pode te ajudar a decidir mais rápido, mas se você está decidindo sobre dados inconsistentes, basicamente vai levar seu produto na direção errada mais rápido. A velocidade não ajuda se a direção está errada.
Não tenho uma resposta 100% definitiva sobre tudo isso. Ninguém tem. O que é claro: a arquitetura de dados não se torna menos importante com AI. Se torna mais importante.
Esta é a base do que pensamos sobre The Modern Growth Stack.
Nas próximas semanas vou descer fase por fase: como definir quais dados você precisa, como desenhar a arquitetura, como implementá-la bem e como ativar.
Em qual fase está sua equipe hoje?